Sistema de formación de vídeo de Ciencias de la Computación del MIT y el Laboratorio de Inteligencia Artificial podría ayudar a los robots a entender cómo los objetos interactúan con el mundo.
Adam Conner-Simons
Para los robots para navegar por el mundo, tienen que ser capaces de hacer suposiciones razonables sobre su entorno y lo que podría suceder durante una secuencia de eventos.
Una manera en que los seres humanos vienen a aprender estas cosas es a través del sonido.Para los bebés, auscultar y pinchar objetos no es sólo diversión; algunos estudios sugieren que en realidad es la forma en que desarrollan una teoría intuitiva de la física. Podría ser que podemos conseguir máquinas de aprender de la misma manera?
Los investigadores de MIT ciencias de la computacion y el laboratorio de inteligencia artficial (CSAIL) han demostrado un algoritmo que efectivamente ha aprendido cómo predecir sonido: Cuando se muestra un clip de vídeo en silencio de un objeto de ser golpeado, el algoritmo puede producir un sonido para el golpe que es lo suficientemente realista para engañar a los espectadores humanos.
Esta «prueba de Turing para el sonido» representa mucho más que un truco equipo inteligente: Los investigadores prevén futuras versiones de algoritmos similares que se utilizan para producir automáticamente efectos de sonido para películas y programas de televisión, así como para ayudar a los robots a entender mejor las propiedades objetos.
Vídeo: MIT CSAIL
«Cuando se ejecuta el dedo por una copa de vino, el sonido que hace refleja la cantidad de líquido que está en él», dice el estudiante de doctorado CSAIL Andrew Owens, que fue el autor principal en un próximo artículo que describe el trabajo. «Un algoritmo que simula tales sonidos pueden revelar información clave acerca de las formas de objetos ‘y tipos de materiales, así como la fuerza y el movimiento de sus interacciones con el mundo.»
El equipo utilizó técnicas del campo de «aprendizaje profundo», que implica equipos de enseñanza para tamizar a través de enormes cantidades de datos para encontrar patrones en su propio. enfoques de aprendizaje profundas son especialmente útiles debido a que liberen los informáticos de tener a mano-diseño de algoritmos y supervisar su progreso.
los co-autores del estudio incluyen recién graduado Phillip Isola y profesores del MIT Edward Adelson, Bill Freeman, Josh McDermott, y Antonio Torralba. El documento se presentará a finales de este mes en la conferencia anual de Visión por Computador y Reconocimiento de Patrones (CVPR) en Las Vegas.
Cómo funciona
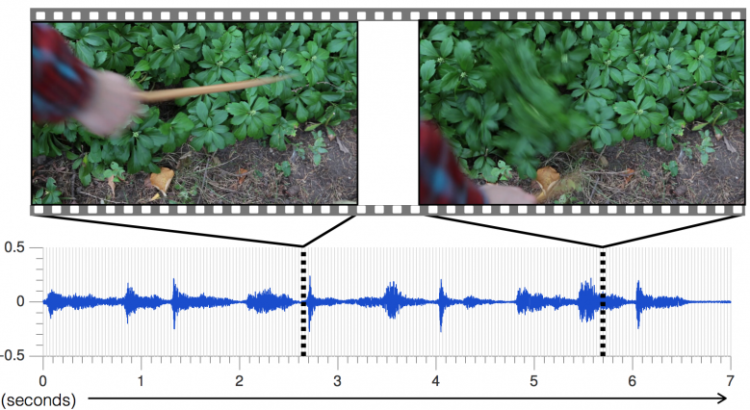
El primer paso para la formación de un algoritmo de producción de sonido es dar suena a estudiar. Durante varios meses, los investigadores registraron cerca de 1.000 vídeos de un estimado de 46.000 sonidos que representan diversos objetos de ser golpeado, raspadas, y pincharon con una baqueta. (Se utilizó un muslo de pollo, ya que proporciona una forma consistente para producir un sonido.)
A continuación, el equipo alimentó a los vídeos a un algoritmo profundo aprendizaje que deconstruye los sonidos y se analizó su tono, el volumen y otras características.
«A continuación, predecir el sonido de un nuevo video, el algoritmo analiza las propiedades de sonido de cada fotograma de ese vídeo, y los compara con los sonidos más similares en la base de datos», dice Owens. «Una vez que el sistema tiene esos bits de audio, que las une para crear un sonido coherente».
El resultado es que el algoritmo puede simular con precisión las sutilezas de los diferentes accesos, de los grifos staccato de una roca a las formas de onda más largas de robo de hiedra. El tono es ningún problema, ya que se puede sintetizar sonidos afectadas van desde los «golpes» de tono bajo de un sofá suave para los agudos «clicks» de una barandilla de madera dura.
«Enfoques actuales en AI sólo se centran en una de las cinco modalidades sensoriales, con investigadores de la visión usando imágenes, los investigadores del habla del uso de audio, y así sucesivamente», dice Abhinav Gupta, profesor asistente de la robótica en la Universidad Carnegie Mellon, que no participó en el estudiar. «Este trabajo es un paso en la dirección correcta para imitar el aprendizaje de la forma que los humanos, mediante la integración de sonido y de la vista.»
Un beneficio adicional de la obra es que la biblioteca de 46.000 sonidos del equipo es gratuito y está disponible para otros investigadores a utilizar. El nombre del conjunto de datos: «Greatest Hits».
Engañando a los seres humanos:
Para probar qué tan realistas fueron los sonidos falsos, el equipo llevó a cabo un estudio en línea en el que los sujetos vieron dos vídeos de colisiones – uno con el sonido de grabación real, y otro con el algoritmo de – y se les hizo cuál era real.
El resultado: Los sujetos tomaron el sonido falsa sobre la real dos veces más que un algoritmo de línea de base. Fueron particularmente engañar por materiales como hojas y la suciedad que tienden a tener menos «limpia» sonidos que, por ejemplo, madera o metal.
Además de eso, el equipo encontró que los sonidos de los materiales revelaron aspectos clave de sus propiedades físicas: Un algoritmo que desarrollaron podría decir la diferencia entre materiales duros y blandos 67 por ciento de las veces.
El trabajo del equipo se alinea con las recientes investigaciones CSAIL en la amplificación de audio y vídeo. Freeman ha ayudado a desarrollar algoritmos que amplifican movimientos captados por el vídeo que son invisibles a simple vista, lo que ha permitido a sus grupos para hacer cosas como hacer que el pulso humano visible e incluso recuperar el habla usando nada más que video de una bolsa de patatas fritas .
Mirando hacia el futuro:
Los investigadores dicen que aún hay espacio para mejorar el sistema. Por ejemplo, si el muslo se mueve de forma errática sobre todo en un video, el algoritmo es más probable que se pierda o alucinaciones una falsa alarma. También está limitado por el hecho de que sólo se aplica a los «sonidos indicados visualmente» – sonidos que son causadas directamente por la interacción física que está siendo representado en el vídeo.
«Desde el soplado suave del viento para el zumbido de los ordenadores portátiles, en un momento dado hay tantos sonidos ambientales que no están relacionados con lo que en realidad estamos mirando», dice Owens. «Lo que sería realmente emocionante es simular alguna manera el sonido que está asociado directamente al menos los elementos visuales.»
El equipo cree que el trabajo futuro en esta área podría mejorar las habilidades de los robots para interactuar con su entorno.
«Un robot podría mirar a una acera e instintivamente sabe que el cemento es dura y la hierba es suave, y por lo tanto sabía lo que pasaría si se intensificaron en cualquiera de ellos», dice Owens. «Ser capaz de predecir el sonido es un primer paso importante hacia el ser capaz de predecir las consecuencias de las interacciones físicas con el mundo.»
El trabajo fue financiado, en parte, por la Fundación Nacional de Ciencia y Shell. Owens también fue apoyado por una beca de investigación Microsoft.
Fuente: http://news.mit.edu/2016/artificial-intelligence-produces-realistic-sounds-0613
Imagen: http://news.mit.edu/sites/mit.edu.newsoffice/files/styles/news_article_image_top_slideshow/public/images/2016/MIT-CSAIL-sound-prediction-algorithm-2_0.png?itok=LIsXEB-x
 Users Today : 54
Users Today : 54 Total Users : 35459520
Total Users : 35459520 Views Today : 74
Views Today : 74 Total views : 3417832
Total views : 3417832