
Esa noche, en 2011, sentó las bases para Unpaywall. Este servicio gratuito localiza artículos de acceso abierto y presenta documentos de pago que han sido legalmente archivados y están disponibles de forma gratuita en otros sitios web para usuarios que de otro modo podrían haber alcanzado una versión de pago. Desde que se lanzó una parte de la tecnología en 2016, se ha vuelto indispensable para muchos investigadores. Y las empresas que ejecutan motores de búsqueda científica establecidos están comenzando a aprovechar Unpaywall.
El 26 de julio, Elsevier anunció planes para integrar Unpaywall en sus búsquedas de bases de datos Scopus, permitiéndole entregar millones de documentos más libres de lectura a los usuarios de lo que lo hace actualmente. La adopción de Scopus de Unpaywall, junto con movimientos similares de otros motores de búsqueda, significa que el contenido de acceso mucho más abierto está ahora al alcance de la mano de los investigadores. Estas ofertas también permiten a los financiadores, bibliotecarios y otros estudiar por completo las tendencias de publicación de acceso abierto por primera vez.
«Unpaywall es un desarrollo pionero», dice Alberto Martín-Martín, que estudia bibliometría y comunicación de la ciencia en la Universidad de Granada en España. «Nos lleva un paso más cerca de lograr una verdadera infraestructura de investigación abierta».
Después de participar en el hackathon 2011, Piwowar y Priem fundaron una organización sin fines de lucro llamada Impactstory, en Vancouver, Canadá, donde refinaron Unpaywall. (Parra ahora es un consultor en el Banco Mundial en Asunción, Paraguay).
La investigación de Priem y Piwowar, publicada en agosto de 2017 en PeerJ Preprints , utilizando Unpaywall, naturalmente, sugiere que casi la mitad de los trabajos de investigación recientes que las personas buscan en línea están disponibles de forma gratuita 1 . Pero, dice Priem, «hay una gran brecha entre la disponibilidad y la capacidad de descubrimiento» de estos documentos, y este es el problema que Unpaywall espera resolver.
Investigación accesible
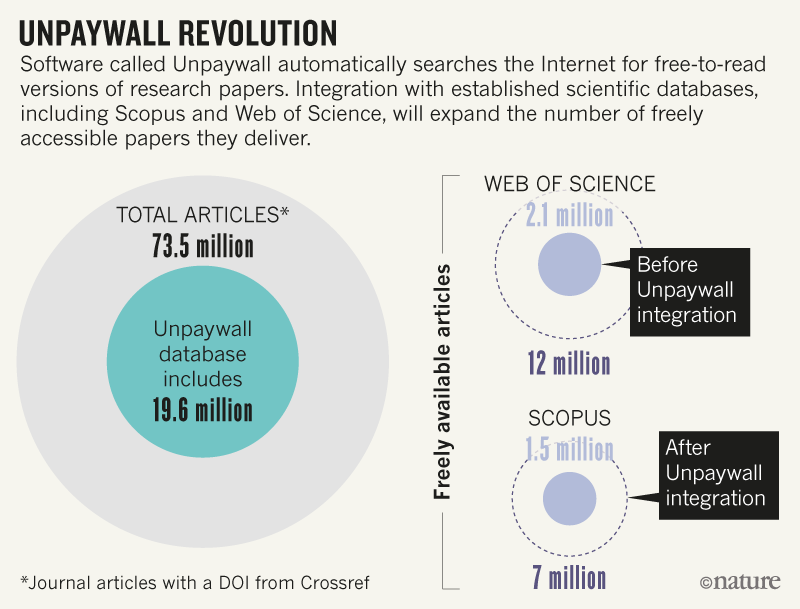
Unpaywall consiste en una base de datos que incluye una lista de casi 20 millones de artículos académicos disponibles gratuitamente. La mayoría de los investigadores acceden a ella utilizando un complemento de navegador que se lanzó en 2017. El servicio funciona buscando la etiqueta digital única de un documento consultado, una cadena de números y letras conocida como DOI o identificador de objeto digital, contra los artículos recopilados. de 50,000 revistas y repositorios.
En junio de 2017, Unpaywall se integró en un popular motor de búsqueda científica llamado Web of Science, que es operado por Clarivate Analytics. Dimensiones, un servicio administrado por Digital Science que se lanzó este año, utilizó Unpaywall desde el principio. Estas compañías, y ahora Elsevier, pagan una tarifa de suscripción por un feed de la base de datos de Unpaywall que se actualiza semanalmente.
Impactstory también ofrece acceso gratuito a la base de datos de Unpaywall (actualizada dos veces al año para los no suscriptores), el complemento del navegador y una interfaz que permite a los programadores interactuar con Unpaywall para recuperar datos.
Desde su lanzamiento, la tecnología de Unpaywall también se ha integrado en muchos sistemas de descubrimiento universidad-biblioteca, de modo que los usuarios pueden encontrar fácilmente versiones de documentos de investigación disponibles libremente en repositorios institucionales. Estos archivos, que son operados por universidades, financiadores y otros, alojan una gran parte de los artículos en la base de datos de Unpaywall, pero fueron difíciles de buscar sistemáticamente en el pasado.
Los científicos que usan Scopus pueden filtrar sus resultados para encontrar documentos disponibles libremente, pero la base de datos se vincula a solo alrededor de 1,5 millones de artículos publicados en revistas de acceso abierto. Una vez que la integración de Unpaywall se complete en noviembre de 2018, las búsquedas realizadas en Scopus para literatura de libre acceso también encontrarán artículos sobre plataformas de editores, incluso si la revista publica una combinación de artículos de acceso abierto y de pago.
Esto aumentará la cantidad de artículos disponibles gratuitamente en Scopus a 7 millones, que todavía son alrededor de 13 millones de artículos menos de los que figuran en la base de datos de Unpaywall como de libre acceso (ver ‘Unpaywall Revolution’). Esta brecha existe porque Scopus no se vinculará a los artículos publicados en los repositorios.
Fuente: Crossref / Unpaywall / Impactstory / Elsevier / Clarivate Analytics
Chris Banks, director de servicios de biblioteca del Imperial College de Londres, dice que está perpleja por el hecho de que Scopus no mostrará la mayoría del contenido de libre lectura en los repositorios. Unpaywall es útil precisamente porque descubre estos documentos difíciles de encontrar, agrega.
Nuevas fronteras
Las bases de datos de citas grandes como Scopus y Web of Science enumeran la mayoría de todos los artículos de investigación. Al integrar sus registros con los datos de Unpaywall, los investigadores pueden medir sistemáticamente la proporción de la literatura que está disponible gratuitamente, una hazaña que antes no era posible. Las búsquedas de Scopus y Web of Science también se pueden filtrar de acuerdo con la nacionalidad de los autores, su institución y el área temática, lo que permite identificar artículos de lectura libre de acuerdo con estos y otros criterios.
El Instituto Nacional de Salud Mental de EE. UU. (NIMH), que cuenta con un presupuesto general de alrededor de US $ 1.500 millones, está trabajando con Impactstory para desarrollar una herramienta a medida que utilice Unpaywall. El objetivo de la agencia es determinar hasta qué punto los investigadores que trabajan en los laboratorios de NIMH en Bethesda, Maryland y en las cercanías de Rockville están poniendo a disposición sus documentos, datos y código fuente de forma gratuita.
Priem dice que Impactstory espera ofrecer un sistema similar al que está desarrollando con NIMH para otras instituciones, mientras que algunas universidades y patrocinadores ya están innovando con Unpaywall. Investigadores de la Universidad de Barcelona y de la Universidad Politécnica de Cataluña en España han utilizado Unpaywall para medir la proporción de artículos publicados por investigadores en sus instituciones que están disponibles gratuitamente.
Para Priem, hacer de Unpaywall una herramienta de referencia para los investigadores es solo el comienzo. El mes pasado, Impactstory obtuvo una subvención de US $ 850,000 para crear un motor de búsqueda dirigido a no científicos. También utilizará inteligencia artificial para resumir los artículos de revistas en su base de datos en lenguaje sencillo, para que los no especialistas puedan comprenderlos. «20 millones de artículos son gratuitos para que todos puedan leer, pero también podrían ser cerrados si no hay forma de que una persona promedio acceda a ellos», dice. «Aún no hemos terminado».
Fuente: https://www.nature.com/articles/d41586-018-05968-3
 Users Today : 58
Users Today : 58 Total Users : 35459964
Total Users : 35459964 Views Today : 73
Views Today : 73 Total views : 3418538
Total views : 3418538